
Déploiement continu vers S3
L’application « Road to Caen » est maintenant bootstrappée. Avant de commencer le développement proprement, il reste à mettre en place le tunnel de déploiement continu, du code créé en local au bucket S3 d’hébergement, déploiement sécurisé par l’exécution automatique des tests unitaires et fonctionnels déjà mis en place.
Hébergement du site sur S3
L’un des objectifs du projet est de réaliser une application serverless. Pour Road to Caen, ce ne devrait pour l’instant pas être compliqué, l’application ne consistant qu’en une application JavaScript. Il suffira donc d’héberger les fichiers statiques sur un Bucket S3, configuré pour pouvoir servir ses fichiers en HTTP.
La manipulation est très simple, et la documentation permet de rapidement mettre en place notre « infrastructure »
Je vais juste revenir sur les points qui me semblent les plus importants.
- Nommage du bucket
Il faut donner le même nom au bucket que l’url du site. Par exemple pour une url mon_site. mon_domaine.com, on nommera le bucket… mon_site. mon_domaine.com
- Création d’un utilisateur IAM, et d’une Policies spécifique pour le bucket
Ensuite, il est obligatoire de créer un utilisateur IAM pour interagir avec notre bucket, afin d’être certain de ne jamais utiliser l’aws_access_key_id et l’aws_secret_access_key de l’utilisateur principal du compte AWS (le root en quelque sorte). Certains s’en sont mordu les doigts.
# Policies appliquée au user IAM
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Stmt1453976839000",
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:PutObjectAcl",
"s3:DeleteObject",
"s3:AddObject"
],
"Resource": [
"arn:aws:s3:::mon_site.mon_domaine.com/*"
]
}
]
}
- Ajout d’une entrée CNAM au DNS de son domaine
Il faut ajouter une entrée CNAM dans les réglages DNS de son domaine.
mon_site CNAME mon_site.mon_domaine.com.s3-website-eu-west-1.amazonaws.com.
Déploiement manuel
Avant de configurer le déploiement automatique, on va tout de même configurer de quoi déployer à la main notre code sur S3. Pour cela, il faut tout d’abord installer awscli. Sur un Mac, on peut utiliser brew :
brew install awscli
Ensuite, on configure un profil spécifique au projet, avec les identifiants de l’utilisateur IAM précédemment créé :
# ~/.aws/config
[default]
output = json
region = us-east-1
[profile IAM_USER_PROFIL]
output = json
region = eu-west-1
aws_access_key_id = IAM_USER_ACCESS_KEY_ID
aws_secret_access_key = IAM_USER_SECRET_ACCESS_KEY
Ne reste plus qu’à ajouter une nouvelle commande à notre fichier makefile:
# makefile
deploy: build
@ echo '* Deploy web app on S3 *'
aws s3 --profile=IAM_USER_PROFIL --region=eu-west-1 sync ./build/ s3://YOUR-BUCKET-NAME/ --delete
Worflow de développement et intégration continue
Le worflow de développement sera très simple; c’est d’ailleurs celui que je trouve le meilleur, même sur les projets plus importants :
- une branche master qui contient le code envoyé sur S3,
- une nouvelle branche par feature développée.
Une fois la feature terminée, elle est intégrée à la branche master via une pull request. C’est à ce moment que l’on va parler d’intégration continue, car cette PR va être automatiquement testée sur Travis. Il suffit pour cela d’ajouter le fichier .travis.yml à la racine du projet :
# .travis.yml
language: node_js
node_js:
- "5.5"
env:
- CXX=g++-4.8
sudo: true
addons:
apt:
sources:
- ubuntu-toolchain-r-test
packages:
- gcc-4.8
- g++-4.8
cache:
directories:
- node_modules
before_script:
- cp -n ./config/test.js.dist ./config/test.js | true
# xvfb va permettre de lancer firefox, utilisé pour les tests fonctionnels
# sans avoir à installer un serveur X
before_install:
- "export DISPLAY=:99.0"
- "sh -e /etc/init.d/xvfb start"
install:
- "make --silent install"
Pour un projet en node, Travis va lancer le script de test déclaré dans le package.json:
"scripts": {
"test": "make test"
},
Il faut évidemment déclarer le dépôt git du projet sur le site de Travis, pour qu’il puisse mettre en place les webhooks lui permettant de savoir quand une PR est réalisée. Travis est gratuit pour les dépôts publics.
Déploiement continu
Pour finir, on va automatiser le déploiement du code sur notre Bucket S3, lorsque la PR (passée au vert sur Travis) est mergée sur la branche master. Pour cela, j’utilise Snap CI (mais il en existe d’autres), qui est tout comme Travis gratuit pour les dépôts git public. L’interface est bien réalisée, et permet de monter un pipeline d’étapes, dont une réalisant le déploiement sur S3. Une étape peut également consistée à lancer les tests une dernière fois avant de déployer, au cas où …
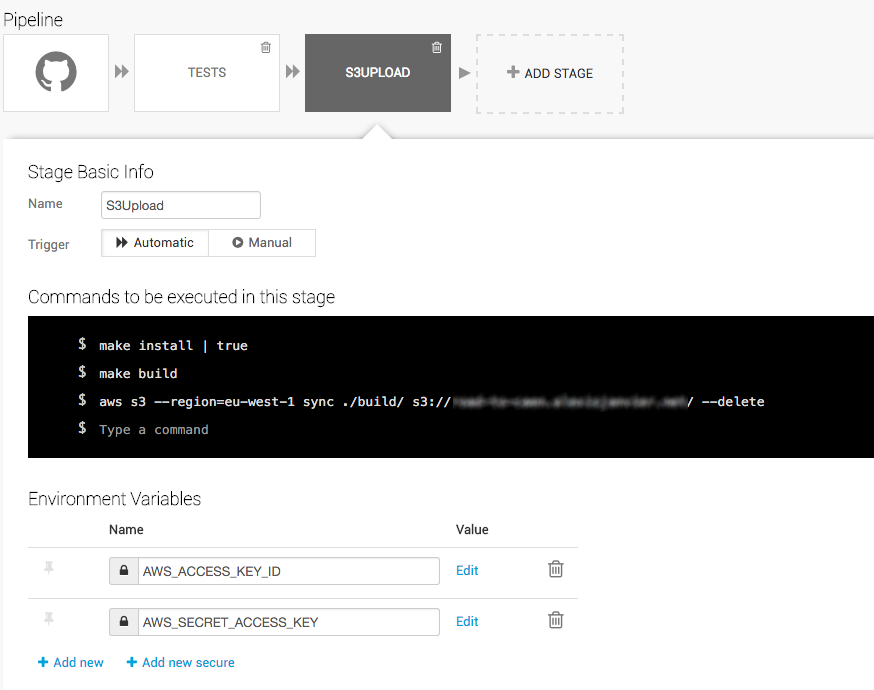
C’est prêt !
Et voilà, on peut commencer à coder en ES6 sur une nouvelle branche. Une fois une feature terminée et testée, on propose le code via une PR sur Github. Si les tests passent tous sur Travis, on merge la PR, et tadam, le code est directement envoyé sur S3 grâce à Snap CI et accessible à la terre entière.