
Applications 12 facteurs: comment validez-vous votre configuration ?
Dès lors que nous livrons notre code sous forme d’image docker, comment s’assurer que la configuration de l’environnement d’exécution sera correcte ?
L’arrivée de Docker a fortement impacté l’architecture de nos applications. Si nous l’avons au début surtout utilisé pour faciliter le développement local, il n’est maintenant pas rare que Docker soit également utilisé en production, et que nous délivrions nos applications sous forme d’images d’un ou plusieurs services. Ce type de conception apporte beaucoup de souplesse en termes de développement, mais aussi son lot de complexité. La méthodologie 12 facteurs est une référence fiable en ce qui concerne les bonnes pratiques d’applications constituées en services.
Ce post se réfère au troisième point de ces 12 facteurs : la configuration.
Le problème
Les 12 facteurs préconisent
une stricte séparation de la configuration et du code. La configuration peut varier substantiellement à travers les déploiements, alors que ce n’est pas le cas du code. [..] Les applications 12 facteurs stockent la configuration dans des variables d’environnement
Jusqu’à présent, nos projets gérés sous Docker utilisent soit Docker Compose, soit Docker Swarm sur les serveurs des clients (nous n’avons pas encore eu l’occasion de mettre en place un Kubernetes par exemple). Le client nous met à disposition une registry pour que nous puissions livrer les images des services, nous maintenons de concert le fichier docker-compose.yml (ou swarm.yml), mais seul le client est responsable au fil des livraisons du fichier x. env des variables d’environnement injectées dans les containers.
// in swarm.yml
version: "3.4"
services:
service1:
image: service1
env_file:
- ./staging.env
service2:
image: service2
env_file:
- ./staging.env
...
Mais comment s’assurer que les variables d’environnement du client soient toutes présentes et valides pour chaque version livrée, tout en lui permettant de ne pas nous les communiquer (accès aux bases de données, à des webservices internes…) ?
Notre solution actuelle
Le solution la plus simple que nous ayons trouvée pour le moment est de livrer au client une image spéfique dont le seul rôle est justement de valider ces variables d’environnement.
Et pour cela, nous avons utilisé un outil javascript de gestion de configuration que nous connaissions bien : convict.
convict permet d’écrire un schema dans lequel la configuration est décrite sous la forme:
VARIABLE_NAME:{
doc:"Variable description",
format:"Le format de la variable. Ce peut-être des formats fournis par convict (`ipaddress`,`port`, ...) ou une fonction de validation",
default:"La valeur par default, ne pouvant être null",
env:"Si la variable spécifiée par env a une valeur, elle écrase la valeur par défaut du paramètre."
}
L’idée va donc être de définir toutes nos variables d’environnement dans ce schema, de pouvoir les décrire avec doc, de leur mettre un valeur par default à et de systématiquement renseigner env.
Par exemple, considérons que la configuration de notre application nécessite trois variables d’environnement NODE_ENV, POSTGRES_PASSWORD et POSTGRES_USER, voici ce que donnera le schema:
// in src/config
const convict = require('convict');
const isNotEmpty = val => {
if (!val.trim()) {
throw new Error('This environment variable cannot be empty');
}
};
const config = convict({
NODE_ENV: {
default: '',
doc: 'The application environment.',
env: 'NODE_ENV',
format: ['production', 'development', 'test'],
},
POSTGRES_PASSWORD: {
default: '',
doc: "PostgreSQL's user password",
env: 'POSTGRES_PASSWORD',
format: isNotEmpty,
},
POSTGRES_USER: {
default: '',
doc: "PostgreSQL's user",
env: 'POSTGRES_USER',
format: isNotEmpty,
},
});
module.exports = config;
Ensuite, la methode validate de convict appliquée sur un fichier de configuration vide config.load({}) va permettre de s’assurer que la validation ne soit faite que sur les variables d’environnement présentes.
// in src/index.js
const { Signale } = require('signale');
const config = require('./config');
const validateConfiguration = () => {
config.load({});
try {
config.validate({ allowed: 'strict' });
signale.success();
} catch (error) {
signale.error(`\\n${error.message}\\n`);
}
};
Remarque: signale est utilisé pour rendre la sortie console plus lisible.
Il ne reste plus qu’à créer une image à partir des deux fichiers index.js et config.js
// in Dockerfile
FROM node:dubnium-alpine
COPY ./src ./validator
WORKDIR /validator
COPY ./package.json ./package.json
COPY ./yarn.lock ./yarn.lock
RUN yarn install --non-interactive --frozen-lockfile
CMD ["node", "index.js", "validate"]
docker build -t myapp_conf_validation:latest
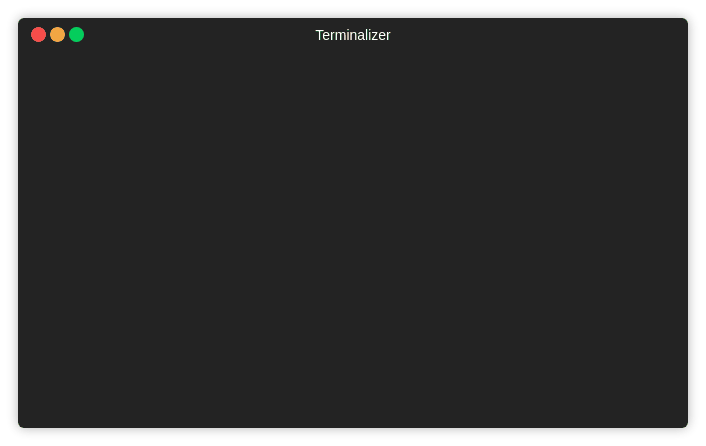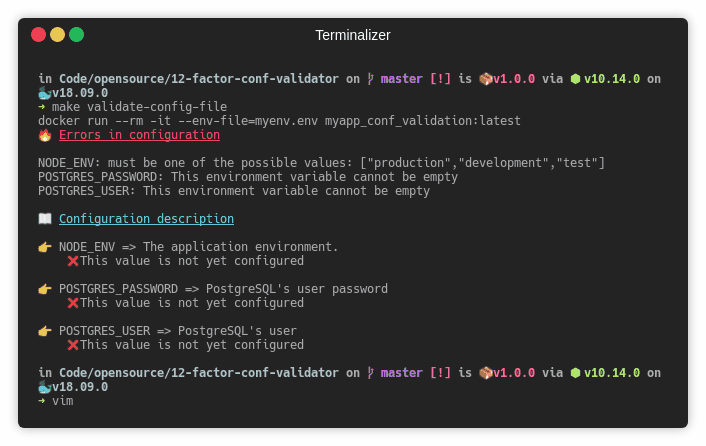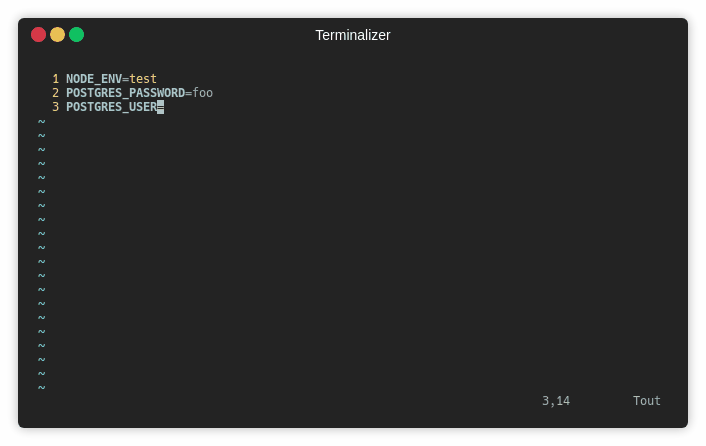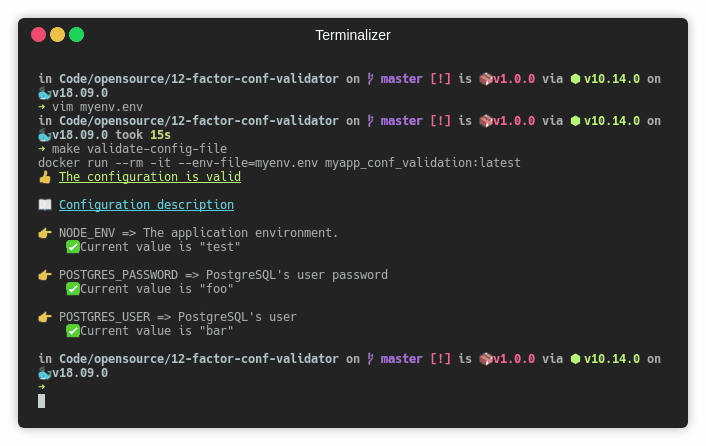
Pour être en mesure de lancer la validation de notre fichier myenv.env:
docker run --rm -it --env-file=myenv.env myapp_conf_validation:latest
Le code est disponible sur Github
Conclusion
Cet outil nous a permis de fluidifier la collaboration avec les responsables de l’exploitation de nos applications et d’éviter plusieurs erreurs lors des déploiements. En cela, c’est un bon outil puisqu’il résout un problème.
Pour autant il reste très imparfait. Particulièrement parce qu’il ne peut pas s’intégrer dans une automatisation des déploiements.
Et vous, comment faites-vous par valider la configuration des vos applications 12 facteurs sur l’ensemble de vos environnements ?